【定时调度】- 01 quartz的基础你真的了解吗
概述
Quartz一款功能丰富、历史悠久,完全基于Java实现的开源任务调度框架,Java调度领域知名度非常高。其简单易用、稳定可靠的特性,使其被很多第三方应用将其当成调度框架基础依赖,如spring boot已内置集成quartz,elastic-job调度框架则将quartz作为其底层基础实现进行封装,xxl-job曾经历史版本也是集成quartz作为其触发实现机制基础,不过在最新版本采用时间轮实现已将quartz移除。
核心三叉戟
使用quartz api时,最核心三件套如下:
 (资料图片)
(资料图片)
Scheduler
SchedulerFactory和Scheduler从名称就很容易识别这里采用工厂设计模式,Scheduler是quartz暴露出来供开发使用的一个最重要组件,从开发者视角来看它就是quartz的门面,对quartz的各种操作都是通过Scheduler进行串联,类似于quartz的大管家、代言人角色。
“这种设计模式在开源框架中很常见,比如
mybatis中SqlSessionFactory和SqlSession,通过给开发者提供大管家组件,通过一个组件串联起所有核心功能,简化了开发人员上手框架难度。
一般一个应用只会对应一个Scheduler实例,不同Scheduler实例之间通过schedulerName进行隔离,所有的quartz数据库表设计中都有sched_name这一列字段,这样Scheduler处理任务时只会操作数据库表中对应schedulerName下的数据。quartz集群就是利用多个Scheduler实例配置相同schedulerName名称,实现多机器同时处理同一个schedulerName下任务来达到集群效果。
“
schedulerName可以通过org.quartz.scheduler.instanceName进行配置,默认名称为QuartzScheduler。
Scheduler操作的主要是JobDetail和Trigger两个组件,JobDetail封装的是任务配置信息,而Trigger触发器封装了任务触发信息,它们是1:N关系,即一个JobDetail可以关联多个Trigger触发器,但是一个Trigger触发器只能绑定到一个Job上。
JobDetail
JobDetail组件封装了quartz调度任务定义信息,下面是JobDetail组件常规使用方式如下:
// JobDataMap实现Map接口,任务调度时存储到JobExecuteContext中,可以传递给Job实例JobDataMap jobDataMap = new JobDataMap();jobDataMap.put("name", "zhangsan");jobDataMap.put("time", System.currentTimeMillis());JobDetail jobDetail = JobBuilder // 绑定任务类 .newJob(QuartzCronJob.class) .storeDurably() // job对应ID .withIdentity("job2", "DEFAULT") .usingJobData(jobDataMap) .build();JobKey jobKey = jobDetail.getKey();if (scheduler.checkExists(jobKey)) { log.warn("调度任务已存在,删除后重新添加:{}", jobKey); scheduler.interrupt(jobKey);//停止JOB /** * deleteJob操作在删除Job之前,会执行unscheduleJob()取消job和trigger关联 */ scheduler.deleteJob(jobKey);}// 将JobDetail任务定义信息插入quartz表scheduler.addJob(jobDetail, true);JobDetail操作比较简单,主要有两点需要注意:1、newJob(Class jobClass)操作绑定任务类,任务类就是封装用户业务逻辑类;2、withIdentity(String name, String group)给该任务设置一个身份ID,后续可以通过该身份ID进行管理,为方便灵活管理quartz抽象出group概念,这样可以批量对一组作业进行批量操作,身份ID使用JobKey进行封装。
使用Scheduler类addJob(JobDetail jobDetail, boolean replace)方法就将创建的Job定义信息添加到quartz中,一般采用数据库持久化模式,即这里就会将Job定义信息插入到qrtz_job_details表中(见下图)。
下面来看下几个关键字段:
sched_name:上面说过,用来关联对应的Scheduler实例is_durable:是否持久化is_nonconcurrent:是否允许同一个作业可以同时多个实例执行,比如一个任务间隔1秒,但其执行时间为2秒,通过该属性控制是否允许同一个作业有多个任务同时允许,参见@DisallowConcurrentExecutionis_update_data: 任务已经执行中,是否允许更新JobDataMap持久化信息,参见@PersistJobDataAfterExecutionrequests_recovery: 故障恢复使用,具体参见后续源码分析job_data:JobDataMap序列化后存储到字段中Trigger
任务定义完成,但是任务按照怎么周期性规则进行触发执行,这就要看Trigger触发器的脸色了
Trigger组件常规使用方式如下:
JobDataMap jobDataMap = new JobDataMap();jobDataMap.put("name", "lisi");jobDataMap.put("address", "China");Trigger trigger = TriggerBuilder .newTrigger() .withIdentity("trigger1", "DEFAULT") .usingJobData(jobDataMap) .startAt(new Date()) .endAt(new Date(System.currentTimeMillis()+38 * 60 * 1000)) .withSchedule(CronScheduleBuilder.cronSchedule("*/10 * * * * ?")) .forJob(new JobKey("job1", "DEFAULT")) .build();//时间TriggerKey triggerKey = trigger.getKey();if(scheduler.checkExists(triggerKey)){ scheduler.unscheduleJob(triggerKey);}//必须绑定jobscheduler.scheduleJob(trigger);和JobDetail类似,主要有两点需要注意:1、同withIdentity(String name, String group),同理给该触发器设置一个身份ID,对应TriggerKey;2、startAt()、endAt()对应启止时间;3、withSchedule(CronScheduleBuilder.cronSchedule("*/10 * * * * ?"));4、forJob(JobKey keyOfJobToFire)将Trigger与Job进行关联,这样才知道触发哪个任务。
最后通过Scheduler类scheduleJob(Trigger trigger)方法就将创建的Trigger定义信息添加到quartz中,一般采用数据库持久化模式,即这里就会将Trigger定义信息插入到触发器相关表中,示例中使用cron触发器,则插入到qrtz_cron_triggers表中(见下图)。
下面我们就来看下任务是咋个触发的。Scheduler类scheduleJob(Trigger trigger)将触发器持久化后,你会发现qrtz_cron_triggers中没有起止时间以及和Job绑定内容,所以,接下来我们看一张非常重要表:qrtz_triggers。scheduleJob()方法在持久化Trigger信息后会同时向qrtz_triggers表插入一条记录(见下图):
qrtz_job_details和qrtz_cron_triggers可以看成静态表,那qrtz_triggers就是运行动态表,保存着任务运行期间数据,且随着运行记录在动态变更,是quartz调度任务运行最重要的一张表,下面我们来看下这张表中几个关键字段:
start_time、end_time: trigger定义时设置的起止时间next_fire_time: 下次触发时间戳prev_fire_time: 上次触发时间戳trigger_state: trigger状态,最常见状态WAITING、ACQUIRED和EXECUTING,分别对应等待(下次触发时间还早) -> 加载到内存中等待(下次触发时间快到了) --> 执行(下次触发时间到了,需要触发任务),具体参见后续源码分析misfire_instr: trigger触发时间过期处理策略,比如本来是10:23:50时间点进行触发,但是由于某些原因在10:23:53秒才检索出来,这是该触发时间点已经过期,misfire_instr就是控制采用什么策略处理该过期任务,是直接丢弃重新计算下次触发时间点、还是一定时间范围内过期的理解执行等等,具体参见后续源码分析job_data: 和JobDetail一样,Trigger也可绑定一个JobDataMap,用于向Job实例传递参数,该字段就是存储Trigger关联的JobDataMap序列化内容quartz基本上就是围绕qrtz_triggers中这几个关键字段实现任务触发,我们连蒙带猜大致可以想出quartz任务调度触发机制粗略流程:
1、通过配置的trigger触发器,计算出下次触发时间,更新到next_fire_time字段,同时更新trigger_state状态为WAITING;
2、quartz线程扫描该表,从表中查询出未来很短一段时间将要触发的记录(比对next_fire_time和当前时间)放入到内存排队队列中,然后将trigger_state更新成ACQUIRED;
3、然后阻塞直到内存排队队列中触发任务到时间点,再触发任务之前,重新计算下次触发时间点,更新到next_fire_time,同时将trigger_state更新为WAITING,然后执行当前任务;
4、由于next_fire_time和trigger_state值更新,重新开始步骤1,就这样循环往复触发下去。
总结
这节从一个使用者角度简单分析quartz核心运行机制,由于只是简单的从外层而未深入剖析源码,只是简单结合数据库表信息对quartz大致的运行机制做个简单猜想,一些重要属性也没展开,带着这些疑问下一节通过源码分析找到真实的答案,一步步加深对quartz运行机制的理解。
标签:
- 【定时调度】- 01 quartz的基础你真的了解吗 Quartz一款功能丰富、历史悠久,完全基于Java实现的开源任务调度框架,Java调度领域知名度非常高。其简单易用、稳定可靠的特性,使其被很多第
-
 喀麦隆参议院选举执政党赢得全部席位 当地时间3月23日,喀麦隆宪法委员会宣布,执政党喀麦隆人民民主联盟在日前举行的参议院选举中赢得全部70个席位。喀麦隆宪法委员会说,此...
喀麦隆参议院选举执政党赢得全部席位 当地时间3月23日,喀麦隆宪法委员会宣布,执政党喀麦隆人民民主联盟在日前举行的参议院选举中赢得全部70个席位。喀麦隆宪法委员会说,此... -
 今日报丨乘的多音字和组词 1、乘的多音字拼音:【chéng】,【shèng】。2、乘的组词:[chéng]乘马、乘车、乘客、乘警、乘便、乘机、乘势、乘法、上乘、下乘。3、[shèn
今日报丨乘的多音字和组词 1、乘的多音字拼音:【chéng】,【shèng】。2、乘的组词:[chéng]乘马、乘车、乘客、乘警、乘便、乘机、乘势、乘法、上乘、下乘。3、[shèn -
 前沿热点:2022年,腾讯员工薪酬逆势涨了21%?数据分析大反转? 2022年,腾讯员工薪酬逆势涨了21%?数据分析大反转?,腾讯,离职,薪资,总薪酬
前沿热点:2022年,腾讯员工薪酬逆势涨了21%?数据分析大反转? 2022年,腾讯员工薪酬逆势涨了21%?数据分析大反转?,腾讯,离职,薪资,总薪酬 -
 法甲:内马尔染红 姆巴佩补时绝杀 北京时间12月29日凌晨4点,法甲联赛第16轮,巴黎圣日耳曼坐镇主场迎战斯特拉斯堡。上半场比赛内马尔任意球传中助攻马尔基
法甲:内马尔染红 姆巴佩补时绝杀 北京时间12月29日凌晨4点,法甲联赛第16轮,巴黎圣日耳曼坐镇主场迎战斯特拉斯堡。上半场比赛内马尔任意球传中助攻马尔基 -
 环球实时:康德乐大药房网购热线_康德乐大药房网购 1、下面为您提供康德乐大药房的官网网址:网页链接康德乐致力于提高医疗保健的成本效益:康德乐的前身是RobertD W
环球实时:康德乐大药房网购热线_康德乐大药房网购 1、下面为您提供康德乐大药房的官网网址:网页链接康德乐致力于提高医疗保健的成本效益:康德乐的前身是RobertD W
- 蚂蚁理财金选助你养成好习惯,稳健理好财 近些年来,基金行情受到了广泛的关注,因为它可以为投资者提供投资机会,并可以帮助投资者进行有效的投资决策。这时候选择一个好平台来进行
-
 德爱威竹炭墙面漆,净味内墙涂料守护每一个家 你知道吗?每年的3月23日是世界气象日,它是由世界气象组织在1960年成立的纪念日,目的是让世界各地的人们认识到绿色环保的重要性。到底要
德爱威竹炭墙面漆,净味内墙涂料守护每一个家 你知道吗?每年的3月23日是世界气象日,它是由世界气象组织在1960年成立的纪念日,目的是让世界各地的人们认识到绿色环保的重要性。到底要 -
 德国卡赫将携全球首发新品亮相第三届消博会 第三届中国国际消费品博览会将于4月11日至15日在海口举行。届时,全球清洁行业领军者德国卡赫将精彩亮相,于200平米的展台内将品牌旗下先进
德国卡赫将携全球首发新品亮相第三届消博会 第三届中国国际消费品博览会将于4月11日至15日在海口举行。届时,全球清洁行业领军者德国卡赫将精彩亮相,于200平米的展台内将品牌旗下先进 - 【定时调度】- 01 quartz的基础你真的了解吗 Quartz一款功能丰富、历史悠久,完全基于Java实现的开源任务调度框架,Java调度领域知名度非常高。其简单易用、稳定可靠的特性,使其被很多第
-
 权威机构眼中的中国城市排名:北上深广杭! 2023年,哪些城市蕴含更大的机遇,更有前途?今天(3月23日),中国发展研究基金会与普华永道联合发布了《机遇之城2023》报
权威机构眼中的中国城市排名:北上深广杭! 2023年,哪些城市蕴含更大的机遇,更有前途?今天(3月23日),中国发展研究基金会与普华永道联合发布了《机遇之城2023》报 -
 半年投资840 亿!千亿光伏龙头晶澳科技宣布再扩产,已有募投项目延期一年 在公布净利翻倍的2022年年报后,晶澳科技再次宣布将对公司一体化产能进行扩建,拟投资128 42亿元在鄂尔多斯高新区建设年产20GW硅片、30GW电池
半年投资840 亿!千亿光伏龙头晶澳科技宣布再扩产,已有募投项目延期一年 在公布净利翻倍的2022年年报后,晶澳科技再次宣布将对公司一体化产能进行扩建,拟投资128 42亿元在鄂尔多斯高新区建设年产20GW硅片、30GW电池 -
 信息:为吸引这家网约车企业落地郑州 河南国资携手海马汽车砸10亿元入股 一家净资产为负数的出行企业,获得了资本的大额投入。海马汽车(SZ000572,股价5 80元,市值95 39亿元)3月23日晚间公告称,拟签署相...
信息:为吸引这家网约车企业落地郑州 河南国资携手海马汽车砸10亿元入股 一家净资产为负数的出行企业,获得了资本的大额投入。海马汽车(SZ000572,股价5 80元,市值95 39亿元)3月23日晚间公告称,拟签署相... -
 劳荣枝案最新进展:辩护律师递交约20万字辩护意见材料 3月23日深夜,大皖新闻记者从劳荣枝家属处获悉,劳荣枝案又有新进展。3月22日下午,最高院劳荣枝案死刑复核庭当面听取了劳荣枝复核辩护律师的
劳荣枝案最新进展:辩护律师递交约20万字辩护意见材料 3月23日深夜,大皖新闻记者从劳荣枝家属处获悉,劳荣枝案又有新进展。3月22日下午,最高院劳荣枝案死刑复核庭当面听取了劳荣枝复核辩护律师的 -
 环球观热点:从“一条河”到“一张名片”——看徐州“还河于民、还绿于城”的辩证法 本报记者蔡洁“归梦如春水,悠悠绕故乡。”春日下的奎河碧波荡漾,蓝色的健身步道蜿蜒曲折,从高处看好似一块蓝绿相间的“画布”。有着4...
环球观热点:从“一条河”到“一张名片”——看徐州“还河于民、还绿于城”的辩证法 本报记者蔡洁“归梦如春水,悠悠绕故乡。”春日下的奎河碧波荡漾,蓝色的健身步道蜿蜒曲折,从高处看好似一块蓝绿相间的“画布”。有着4... -
 德州市德城公安掀起“反诈风暴” “凡是刷单都是诈骗……”近日,德州学院举行了一场别开生面的“反诈”主题班会。德州市德城区副区长、公安分局局长郑虎亲自带领反诈宣...
德州市德城公安掀起“反诈风暴” “凡是刷单都是诈骗……”近日,德州学院举行了一场别开生面的“反诈”主题班会。德州市德城区副区长、公安分局局长郑虎亲自带领反诈宣... -
 农本咨询创始人贾枭: 坚持“一牌一品”模式 深化“果旅融合” 2022年1月1日,三亚芒果区域公用品牌亮相北京天安门广场《辉煌中国》主题展,一句“三亚芒果,爱上三亚的另一个理由!”广告语,吸引众...
农本咨询创始人贾枭: 坚持“一牌一品”模式 深化“果旅融合” 2022年1月1日,三亚芒果区域公用品牌亮相北京天安门广场《辉煌中国》主题展,一句“三亚芒果,爱上三亚的另一个理由!”广告语,吸引众... - 全球今头条!三亚清明祭扫昨起开放预约 预计本周末迎首个祭扫高峰 为做好清明祭扫安全服务保障工作,市殡葬管理服务中心发布通告,4月1日至5日到市荔仙园公墓祭扫需要预约,3月23日起开放预约通道。
-
 热门:Counterpoint:2022年全球ODM/IDH智能手机出货量同比下降5%
IT之家3月24日消息,CounterpointResearch最新报告显示,智能手机ODM IDH出货量在2022年同比下降了5%。
热门:Counterpoint:2022年全球ODM/IDH智能手机出货量同比下降5%
IT之家3月24日消息,CounterpointResearch最新报告显示,智能手机ODM IDH出货量在2022年同比下降了5%。 -
 每日播报!江苏徐州:多种“智慧招商”发力 奏响产业强市“最强音” 本报记者郑微3月20日,在徐州(北京)投资洽谈会上,首批30个“揭榜式招商”项目公开发布,涉及徐州13个县(市、区)板块,项目涵盖“34...
每日播报!江苏徐州:多种“智慧招商”发力 奏响产业强市“最强音” 本报记者郑微3月20日,在徐州(北京)投资洽谈会上,首批30个“揭榜式招商”项目公开发布,涉及徐州13个县(市、区)板块,项目涵盖“34... -
 一加Nord CE3 Lite手机定档4月4日,Nord Buds 2蓝牙耳机同步发布
IT之家3月24日消息,一加推特更新推文,宣布一加NordCE3Lite手机将于4月4日19:00(IT之家注:北京时间21:30)
一加Nord CE3 Lite手机定档4月4日,Nord Buds 2蓝牙耳机同步发布
IT之家3月24日消息,一加推特更新推文,宣布一加NordCE3Lite手机将于4月4日19:00(IT之家注:北京时间21:30) -
 环球新资讯:恒大汽车:口袋空空的梦想家 2019年3月,许家印在中国恒大(03333 HK)业绩发布会上放出豪言:恒大要在未来5年打造成全球第一的汽车集团!当时,在场有记者对恒大的债务问题
环球新资讯:恒大汽车:口袋空空的梦想家 2019年3月,许家印在中国恒大(03333 HK)业绩发布会上放出豪言:恒大要在未来5年打造成全球第一的汽车集团!当时,在场有记者对恒大的债务问题 -
 全球讯息:嫦娥五号样品研究揭示月球年轻火山活动奥秘
IT之家3月24日消息,据中科院紫金山天文台网站,中科院紫金山天文台天体化学团队近日联合中国科学技术大学、美国佛罗里达大学、中国地质...
全球讯息:嫦娥五号样品研究揭示月球年轻火山活动奥秘
IT之家3月24日消息,据中科院紫金山天文台网站,中科院紫金山天文台天体化学团队近日联合中国科学技术大学、美国佛罗里达大学、中国地质... -
 【天天热闻】Redmi Note 12系列手机全球版发布:新增4G版本,199 欧元起
IT之家3月24日消息,小米近日举行了主题为“thirdtime sacharm”的发布活动,为海外用户带来全新的RedmiNote12系
【天天热闻】Redmi Note 12系列手机全球版发布:新增4G版本,199 欧元起
IT之家3月24日消息,小米近日举行了主题为“thirdtime sacharm”的发布活动,为海外用户带来全新的RedmiNote12系 -
 江苏徐州:15分钟政务服务圈“圈”出百姓满满幸福感 春日的阳光洒进徐州市政务服务中心大厅,墙上“为人民服务”的红色大字醒目,窗口工作人员在为市民办理业务,大厅内,各项业务忙碌而有...
江苏徐州:15分钟政务服务圈“圈”出百姓满满幸福感 春日的阳光洒进徐州市政务服务中心大厅,墙上“为人民服务”的红色大字醒目,窗口工作人员在为市民办理业务,大厅内,各项业务忙碌而有... -
 世界观察:曲阜:智慧化+信息化 促进文明规范执法 “现在,我们一线执法队员配备了移动执法终端、胸卡式执法记录仪和便携式蓝牙打印机,通过‘互联网+移动执法’的智慧化、信息化执法模式...
世界观察:曲阜:智慧化+信息化 促进文明规范执法 “现在,我们一线执法队员配备了移动执法终端、胸卡式执法记录仪和便携式蓝牙打印机,通过‘互联网+移动执法’的智慧化、信息化执法模式... - 观速讯丨山东实施专项行动打响“工赋山东”品牌 3月24日,记者从山东省工业和信息化厅获悉,山东将深入实施“工赋山东”专项行动,打响“工赋山东”品牌,到2023年底,新培育新一代信息...
-
 安徽电影集团星空校园院线携手华娱众禾为影视教育产业助力 近日,安徽电影集团星空校园院线主任郭婷婷、靳涤风、余姚琪一行来访华娱众禾(北京)教育科技有限公司,华娱影视公司总经理孟秀莉对郭婷婷
安徽电影集团星空校园院线携手华娱众禾为影视教育产业助力 近日,安徽电影集团星空校园院线主任郭婷婷、靳涤风、余姚琪一行来访华娱众禾(北京)教育科技有限公司,华娱影视公司总经理孟秀莉对郭婷婷 -
 赶鸭子上架什么意思 赶鸭子上架下一句歇后语 赶鸭子上架什么意思赶鸭子上架的意思是:比喻强迫去做能力达不到的事情,凡是养过鸭子的人都知道,鸭子是不会像鸡一样上架的,所以说养鸭子
赶鸭子上架什么意思 赶鸭子上架下一句歇后语 赶鸭子上架什么意思赶鸭子上架的意思是:比喻强迫去做能力达不到的事情,凡是养过鸭子的人都知道,鸭子是不会像鸡一样上架的,所以说养鸭子 -
 壶口瀑布在哪里 壶口瀑布门票多少钱一张? 壶口瀑布在哪里黄河壶口瀑布在陕西省和山西省。壶口瀑布是国家级风景名胜区,国家AAAA级旅游景区。西临陕西省延安市宜川县壶口乡,东濒山西
壶口瀑布在哪里 壶口瀑布门票多少钱一张? 壶口瀑布在哪里黄河壶口瀑布在陕西省和山西省。壶口瀑布是国家级风景名胜区,国家AAAA级旅游景区。西临陕西省延安市宜川县壶口乡,东濒山西 -
 女子实名举报医生丈夫出轨 出轨闹到单位会被辞退吗? 女子实名举报医生丈夫出轨时间飞逝,岁月如梭,2023年已经进入了3月24日;经历了春节假期短暂的休整,大家都以最饱满的精神状态投入新一年的
女子实名举报医生丈夫出轨 出轨闹到单位会被辞退吗? 女子实名举报医生丈夫出轨时间飞逝,岁月如梭,2023年已经进入了3月24日;经历了春节假期短暂的休整,大家都以最饱满的精神状态投入新一年的 -
 朴叙俊在韩国什么咖位 朴叙俊在韩国算几线? 朴叙俊在韩国什么咖位朴叙俊在韩国算很红的男星,咖位算一线与二线之间。这个男明星很特别,他优势太过明显,大一就服完兵役,服完兵役后出
朴叙俊在韩国什么咖位 朴叙俊在韩国算几线? 朴叙俊在韩国什么咖位朴叙俊在韩国算很红的男星,咖位算一线与二线之间。这个男明星很特别,他优势太过明显,大一就服完兵役,服完兵役后出 -
 泮塘五秀是指什么 六斋菜是哪些东西? 泮塘五秀是指什么泮塘五秀指的是泮塘盛产的菱角、慈菇、马蹄、胶笋和莲藕五样植物。话说,从前泮塘的村民经常去西禅寺参拜的,跟西禅寺的和
泮塘五秀是指什么 六斋菜是哪些东西? 泮塘五秀是指什么泮塘五秀指的是泮塘盛产的菱角、慈菇、马蹄、胶笋和莲藕五样植物。话说,从前泮塘的村民经常去西禅寺参拜的,跟西禅寺的和 -
 丽江在哪里 去丽江旅游攻略和费用是多少? 丽江在哪里
丽江在哪里 去丽江旅游攻略和费用是多少? 丽江在哪里 -
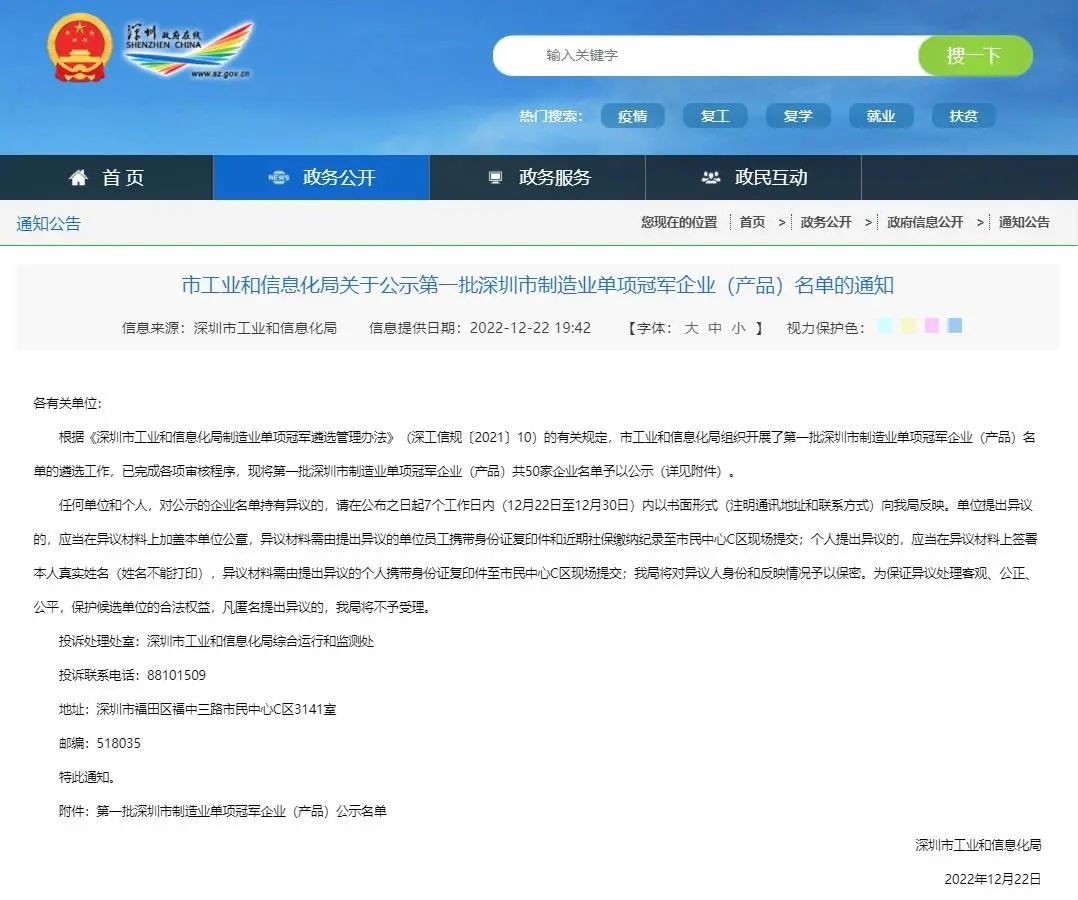 【喜报】德力凯被评定为第一批深圳市制造业 单项冠军企业(产品) 2022年12月22日,深圳市德力凯医疗设备股份有限公司被认定为第一批深圳市制造业单项冠军企业(产品)!深圳市工业和信息化局公示名单如下:
【喜报】德力凯被评定为第一批深圳市制造业 单项冠军企业(产品) 2022年12月22日,深圳市德力凯医疗设备股份有限公司被认定为第一批深圳市制造业单项冠军企业(产品)!深圳市工业和信息化局公示名单如下: -
 郭敬明的代表作小说有哪些 郭敬明和谁有关系? 郭敬明的代表作小说有哪些郭敬明代表作小说有:1、《爵迹》《爵迹》是作家郭敬明创作的长篇小说,该小说设定在虚构的奥汀大陆,讲述了福泽
郭敬明的代表作小说有哪些 郭敬明和谁有关系? 郭敬明的代表作小说有哪些郭敬明代表作小说有:1、《爵迹》《爵迹》是作家郭敬明创作的长篇小说,该小说设定在虚构的奥汀大陆,讲述了福泽 -
 大熊猫被小鸟薅毛毫无反应淡定干饭 大熊猫几点吃午饭? 大熊猫被小鸟薅毛毫无反应淡定干饭近日,北京。有网友拍到了一段大熊猫被小鸟薅毛的有趣场景,视频中,一只小鸟悄悄接近正在吃竹子的大熊猫
大熊猫被小鸟薅毛毫无反应淡定干饭 大熊猫几点吃午饭? 大熊猫被小鸟薅毛毫无反应淡定干饭近日,北京。有网友拍到了一段大熊猫被小鸟薅毛的有趣场景,视频中,一只小鸟悄悄接近正在吃竹子的大熊猫 -
 闽南语和粤语是一样的吗 广东话是闽南语还是粤语? 闽南语和粤语是一样的吗闽南语和粤语是不一样的,闽南语主要分布福建泉州、漳州、厦门、龙岩新罗区的大部分和漳平市大部分、三明地区大田大
闽南语和粤语是一样的吗 广东话是闽南语还是粤语? 闽南语和粤语是一样的吗闽南语和粤语是不一样的,闽南语主要分布福建泉州、漳州、厦门、龙岩新罗区的大部分和漳平市大部分、三明地区大田大 -
 世界四大历史文化名城是哪四个 西安是世界历史文化名城吗? 世界四大历史文化名城是哪四个世界四大历史文化名城(世界四大文明古)都是指意大利罗马、希腊雅典、埃及开罗和中国西安;另有一说为意大利罗
世界四大历史文化名城是哪四个 西安是世界历史文化名城吗? 世界四大历史文化名城是哪四个世界四大历史文化名城(世界四大文明古)都是指意大利罗马、希腊雅典、埃及开罗和中国西安;另有一说为意大利罗 -
 天天热议:成交56300吨! 逆向采购会首日签约金额高达5.21亿元 “春橘橙果肉紧实,口感甜,有采购需求的话,我们进一步谈谈?”“石榴不是八九月份才上市吗?现在才三月,这里竟然有新鲜石榴。
天天热议:成交56300吨! 逆向采购会首日签约金额高达5.21亿元 “春橘橙果肉紧实,口感甜,有采购需求的话,我们进一步谈谈?”“石榴不是八九月份才上市吗?现在才三月,这里竟然有新鲜石榴。 -
 天天热点评!开往春天的列车 带你穿越最美花海 伴着芬芳的气息,看随风起舞的油菜花田;伴着娑婆的树影,看层林尽染的山川河流;伴着巍峨的长城,看扑面而来的山桃花海……春日风光好...
天天热点评!开往春天的列车 带你穿越最美花海 伴着芬芳的气息,看随风起舞的油菜花田;伴着娑婆的树影,看层林尽染的山川河流;伴着巍峨的长城,看扑面而来的山桃花海……春日风光好... - 全球视点!鄱阳湖在哪个省份?潘阳湖面积是多少平方千米? 1、鄱阳湖位于北纬28°22′至29°45′,东经115°47′至116°45′。2、地处江西省的北部,长江中下游南岸。3、鄱阳湖以松门山为界,分为南北两部分,
-
 每日视讯:269 元,OPPO 100W 双口超级闪充充电器今日开售
IT之家3月24日消息,OPPO100W双口超级闪充充电器将于今日上午10:00开售,配备1A1C双接口,采用90°折叠插脚设计方便收纳
每日视讯:269 元,OPPO 100W 双口超级闪充充电器今日开售
IT之家3月24日消息,OPPO100W双口超级闪充充电器将于今日上午10:00开售,配备1A1C双接口,采用90°折叠插脚设计方便收纳 -
 【热闻】湖南一高校根据食堂消费大数据确定“低消费”对象 100万元餐补将“偷偷”... “100万元餐费偷偷打进学生饭卡里!”近日,因悄悄给学生发放餐补,湖南科技大学被网友羡慕地称为“别人的学校”。3月22日,北京青年报...
【热闻】湖南一高校根据食堂消费大数据确定“低消费”对象 100万元餐补将“偷偷”... “100万元餐费偷偷打进学生饭卡里!”近日,因悄悄给学生发放餐补,湖南科技大学被网友羡慕地称为“别人的学校”。3月22日,北京青年报... - 喀麦隆参议院选举执政党赢得全部席位 当地时间3月23日,喀麦隆宪法委员会宣布,执政党喀麦隆人民民主联盟在日前举行的参议院选举中赢得全部70个席位。喀麦隆宪法委员会说,此...
-
 【世界报资讯】消息称 Sonos 将于今年 9 月推出第二代 Move 便携式音箱
IT之家3月24日消息,根据国外科技媒体TheVerge报道,Sonos(搜诺思)将于2023年9月推出第二代Move便携式音箱。报道
【世界报资讯】消息称 Sonos 将于今年 9 月推出第二代 Move 便携式音箱
IT之家3月24日消息,根据国外科技媒体TheVerge报道,Sonos(搜诺思)将于2023年9月推出第二代Move便携式音箱。报道 -
 【焦点热闻】3月27日至31日 海南部分道路实施交通管制 3月23日,记者从交警部门获悉,为确保博鳌亚洲论坛2023年年会期间警卫线路交通安全、畅通、有序,海南省公安厅交通警察总队决定对我省部分道路
【焦点热闻】3月27日至31日 海南部分道路实施交通管制 3月23日,记者从交警部门获悉,为确保博鳌亚洲论坛2023年年会期间警卫线路交通安全、畅通、有序,海南省公安厅交通警察总队决定对我省部分道路 -
 世界看点:免费!三亚今年将为适龄女生接种HPV疫苗 为推进健康海南行动,促进宫颈癌综合防治工作,近日,三亚市卫生健康委员会、三亚市教育局印发《2023年三亚市适龄女生HPV疫苗接种项目实施方案
世界看点:免费!三亚今年将为适龄女生接种HPV疫苗 为推进健康海南行动,促进宫颈癌综合防治工作,近日,三亚市卫生健康委员会、三亚市教育局印发《2023年三亚市适龄女生HPV疫苗接种项目实施方案 -
 高薪招聘司机暗藏“以租代购”猫腻 专家提醒,求职时勿轻信口头承诺,警惕合同中贷款、租赁等字样阅读提示应聘货运司机后,不仅对方承诺的高薪、稳定货源没有兑现,还陷入...
高薪招聘司机暗藏“以租代购”猫腻 专家提醒,求职时勿轻信口头承诺,警惕合同中贷款、租赁等字样阅读提示应聘货运司机后,不仅对方承诺的高薪、稳定货源没有兑现,还陷入... -
 天天头条:氮气密度是多少?氮气密度资料介绍? 1、氮气在通常情况下密度比空气小 在确定的状态下,氮气的密度是确定的,而空气由于成分复杂,密度不定,可能某地的空气中含有较多的污...
天天头条:氮气密度是多少?氮气密度资料介绍? 1、氮气在通常情况下密度比空气小 在确定的状态下,氮气的密度是确定的,而空气由于成分复杂,密度不定,可能某地的空气中含有较多的污... - 江西上饶在哪里?江西上饶资料介绍? 1、截至2019年,江西上饶隶属于江西省。2、江西省下辖11个地级为南昌市、九江市、上饶市、抚州市、宜春市、吉安市、赣州市、景德镇市、萍乡市
-
 【环球时快讯】什么是cdr文件?cdr文件怎么打开? 1、什么是cdr文件?可能很多朋友不太了解,因为平时不怎么联系,所以不知道用什么打开cdr格式的文件。下面简单介绍一下。2、什么是cdr文件?3
【环球时快讯】什么是cdr文件?cdr文件怎么打开? 1、什么是cdr文件?可能很多朋友不太了解,因为平时不怎么联系,所以不知道用什么打开cdr格式的文件。下面简单介绍一下。2、什么是cdr文件?3 -
 三亚西水中调工程引水隧洞段全线贯通 预计明年8月实现功能性通水 3月23日,随着三亚西水中调工程(一期)原水工程部分5 至6 支洞主洞段最后一声爆破声响起,该工程28 1公里引水隧洞段实现全线贯通,标志着海南
三亚西水中调工程引水隧洞段全线贯通 预计明年8月实现功能性通水 3月23日,随着三亚西水中调工程(一期)原水工程部分5 至6 支洞主洞段最后一声爆破声响起,该工程28 1公里引水隧洞段实现全线贯通,标志着海南 - 三亚丨已有3200多人取得游艇驾驶证 3月22日,由三亚海事局主办、海南鸿洲游艇产业发展(投资)集团承办的首期“船员夜校”正式开讲,来自辖区各租赁游艇俱乐部的近百名游艇...
-
 环球观天下!从3月至6月底 河北实施重大交通基础设施项目用地保障集中攻坚行动 聚合力协调推进19个重大交通基础设施项目用地手续办理河北日报讯(记者苑立立通讯员宋海娟)为强化土地要素保障,持续优化营商环境,近...
环球观天下!从3月至6月底 河北实施重大交通基础设施项目用地保障集中攻坚行动 聚合力协调推进19个重大交通基础设施项目用地手续办理河北日报讯(记者苑立立通讯员宋海娟)为强化土地要素保障,持续优化营商环境,近... -
 淋漓是什么意思?淋漓出自哪里? 淋漓的意思,淋漓这个很多人还不知道,小飞来为大家解答以上的问题。现在让我们一起来看看吧!1、基本意义:指液体缓缓地淌下,即流滴的...
淋漓是什么意思?淋漓出自哪里? 淋漓的意思,淋漓这个很多人还不知道,小飞来为大家解答以上的问题。现在让我们一起来看看吧!1、基本意义:指液体缓缓地淌下,即流滴的...
热门资讯
- 德爱威竹炭墙面漆,净味内墙涂料守护每一个家 你知道吗?每年的3月23日是世界气...
- 德国卡赫将携全球首发新品亮相第三届消博会 第三届中国国际消费品博览会将于4...
- 安徽电影集团星空校园院线携手华娱众禾为影视教育产业助力 近日,安徽电影集团星空校园院线主...
- 【喜报】德力凯被评定为第一批深圳市制造业 单项冠军企业(产品) 2022年12月22日,深圳市德力凯医疗...
观察
图片新闻
- 全球今头条!三亚清明祭扫昨起开放预约 预计本周末迎首个祭扫高峰 为做好清明祭扫安全服务保障工作,...
- 农本咨询创始人贾枭: 坚持“一牌一品”模式 深化“果旅融合” 2022年1月1日,三亚芒果区域公用品...
- 天天热议:成交56300吨! 逆向采购会首日签约金额高达5.21亿元 “春橘橙果肉紧实,口感甜,有采购...
- 三亚丨已有3200多人取得游艇驾驶证 3月22日,由三亚海事局主办、海南...
精彩新闻
-
 热头条丨eml文件是什么格式?eml文件怎么打开? 1、EML文件本质上是电子邮件。2、...
热头条丨eml文件是什么格式?eml文件怎么打开? 1、EML文件本质上是电子邮件。2、... - 热点在线丨标准差怎么计算?标准差的计算公式是什么? 1、标准差(StandardDeviation),...
- 观速讯丨如何设置单反相机防抖?相机防抖的设置方法? 1、教你如何设置单反相机防抖:2、...
-
 全球快播:显示器分辨率最佳参数是多少?屏幕分辨率标准是什么? 1、屏幕分辨率概述:2、分辨率是屏...
全球快播:显示器分辨率最佳参数是多少?屏幕分辨率标准是什么? 1、屏幕分辨率概述:2、分辨率是屏... - 华为p30怎么样?华为p30手机有哪些亮点? 华为全新的p30有很多亮点,吸引了...
-
 三亚首个农村宅基地盘活利用项目动工 微风拂堤、春启新程,3月18日上午...
三亚首个农村宅基地盘活利用项目动工 微风拂堤、春启新程,3月18日上午... -
 当前聚焦:江西分宜惊现大批明清城墙砖 近日,江西省新余市分宜县博物馆工...
当前聚焦:江西分宜惊现大批明清城墙砖 近日,江西省新余市分宜县博物馆工... - 一年四季有书香 贾汪风景“读”好 “新时代乡村阅读榜样”领读活动走...
-
 世界观热点:让『拿地即开工』成为常态 本报讯(记者范海杰)记者日前从市...
世界观热点:让『拿地即开工』成为常态 本报讯(记者范海杰)记者日前从市... - 世界资讯:加快施工进度 确保汛期前完工 本报讯(记者宋新通讯员侯冉冉)“...
- 今日报丨乘的多音字和组词 1、乘的多音字拼音:【chéng】,【...
-
 OPPO Pad 2 平板电脑今日开售:搭载天玑 9000 处理器,2999 元起
IT之家3月24日消息,OPPOPad2平板...
OPPO Pad 2 平板电脑今日开售:搭载天玑 9000 处理器,2999 元起
IT之家3月24日消息,OPPOPad2平板... -
 我市加速构建“15分钟政务服务圈” 彭城街道便民服务中心大厅。图片由...
我市加速构建“15分钟政务服务圈” 彭城街道便民服务中心大厅。图片由... -
 全球首款双座水上电动飞机正式交付
IT之家3月24日消息,从沈阳航空航...
全球首款双座水上电动飞机正式交付
IT之家3月24日消息,从沈阳航空航... -
 “政策+活动”双轮驱动,2023上海促消费这样放大招 2022年,上海作为我国最大的消费城...
“政策+活动”双轮驱动,2023上海促消费这样放大招 2022年,上海作为我国最大的消费城... -
 全球微速讯:三亚崖州湾科技城持续优化惠企政策 助力高科技民营企业高质量发展 三亚崖州湾科技城发展日新月异,本...
全球微速讯:三亚崖州湾科技城持续优化惠企政策 助力高科技民营企业高质量发展 三亚崖州湾科技城发展日新月异,本... - 【全球播资讯】“走进北院门 读懂莲湖区”老字号读懂西安系列活动3月21日启动 吃饭时来瓶“冰峰”,下班回家路上...
-
 【新要闻】山西省拟对12家重点企业进行落户奖补 近日,山西省商务厅公示了山西2022...
【新要闻】山西省拟对12家重点企业进行落户奖补 近日,山西省商务厅公示了山西2022... -
 环球简讯:关键节点取得关键突破 东部绕越高速公路取得关键突破。本...
环球简讯:关键节点取得关键突破 东部绕越高速公路取得关键突破。本... -
 当前热讯:4499 元起,OPPO Find X6 / Pro 手机今日开售
IT之家3月24日消息,OPPOFindX6系...
当前热讯:4499 元起,OPPO Find X6 / Pro 手机今日开售
IT之家3月24日消息,OPPOFindX6系... -
 苹果用户反馈 macOS 13.3 Beta 版本已修复 SMB 无法共享文件问题
IT之家3月24日消息,苹果于今年1月...
苹果用户反馈 macOS 13.3 Beta 版本已修复 SMB 无法共享文件问题
IT之家3月24日消息,苹果于今年1月... -
 世界快讯:推进“五社联动” 关爱“一小一老”长春市朝阳区社工周系列活动启动 3月23日,以“推进‘五社联动’关...
世界快讯:推进“五社联动” 关爱“一小一老”长春市朝阳区社工周系列活动启动 3月23日,以“推进‘五社联动’关... -
 每日视讯:世界防治结核病日|手绘漫画告诉你结核病N个“真相” 今年3月24日是第28个“世界防治结...
每日视讯:世界防治结核病日|手绘漫画告诉你结核病N个“真相” 今年3月24日是第28个“世界防治结... - 前沿热点:2022年,腾讯员工薪酬逆势涨了21%?数据分析大反转? 2022年,腾讯员工薪酬逆势涨了21%...
-
 环球快看:iQOO Z7 手机今日开售:骁龙 782G、120W 快充,1599 元起
IT之家3月24日消息,iQOOZ7手机于3...
环球快看:iQOO Z7 手机今日开售:骁龙 782G、120W 快充,1599 元起
IT之家3月24日消息,iQOOZ7手机于3... - 英伟达 531.41 显卡驱动发布:支持《暗黑破坏神 IV》公测版
IT之家3月23日消息,英伟达现已发...
-
 每日速看!Epic 喜加一:《终极象棋》、《战舰世界》新手包免费领
IT之家3月23日消息,Epic本周喜加...
每日速看!Epic 喜加一:《终极象棋》、《战舰世界》新手包免费领
IT之家3月23日消息,Epic本周喜加... - 新海诚动画电影《铃芽之旅》今日内地上映,终极预告发布
IT之家3月24日消息,新海诚导演新...
- 快播:柬埔寨首相洪森:合作才能共赢,中国发展令东盟受益 中新网3月23日电据《柬中时报》报...
- 英国央行宣布加息25个基点 当地时间3月23日,英国央行宣布加...
- 全球看热讯:联想发布拯救者 Y34wz-30 带鱼屏显示器:mini-LED 背光
IT之家3月23日消息,联想今日发布...
-
 今日聚焦!专访:中国先进的气象理念造福国际社会——访世界气象组织助理秘书长张文建 新华社日内瓦3月23日电专访:中国...
今日聚焦!专访:中国先进的气象理念造福国际社会——访世界气象组织助理秘书长张文建 新华社日内瓦3月23日电专访:中国... - 法甲:内马尔染红 姆巴佩补时绝杀 北京时间12月29日凌晨4点,法甲联...
- 环球实时:康德乐大药房网购热线_康德乐大药房网购 1、下面为您提供康德乐大药房的官...
-
 环球即时:一川烟雨入画来|“旅游画笔”描绘乡村振兴新画卷 “独泛扁舟映绿杨,嘉陵江水色苍苍...
环球即时:一川烟雨入画来|“旅游画笔”描绘乡村振兴新画卷 “独泛扁舟映绿杨,嘉陵江水色苍苍... - 海口市秀英区与定安县实现政务服务“跨市县通办” 3月23日下午,海口市秀英区与定安...
- 训练ChatGPT模型不付钱?美国新闻集团拟起诉微软、谷歌、OpenAI
IT之家3月23日消息,自ChatGPT风靡...
-
 看机器人比武!首届大湾区数智竞技格斗机器人大赛在深举办 撞击的尖鸣,翻飞的木屑,四溅的花...
看机器人比武!首届大湾区数智竞技格斗机器人大赛在深举办 撞击的尖鸣,翻飞的木屑,四溅的花... - 聊一款旗舰级“薄型游戏本”
IT之家编者寄语:笔吧评测室作为老...
-
 全球关注:知名硬件评测频道“Linus Tech Tips”被黑,账号改名特斯拉
IT之家3月23日消息,知名硬件评测...
全球关注:知名硬件评测频道“Linus Tech Tips”被黑,账号改名特斯拉
IT之家3月23日消息,知名硬件评测... -
 中国移动董事长杨杰:今年收入规模超万亿应该没有任何问题
IT之家3月23日消息,中国移动今日...
中国移动董事长杨杰:今年收入规模超万亿应该没有任何问题
IT之家3月23日消息,中国移动今日... - 快消息!《巫师3:狂猎》PC 热修复补丁推出:改善 DLSS 3 运行稳定性
IT之家3月23日消息,《巫师3狂猎》...
- 【世界播资讯】邮储银行重庆分行开展“邮爱公益”宣传活动 3月20日,中国邮政储蓄银行(以下...
-
 重庆轨道交通18号线工程实现全线洞通 3月23日,重庆市住建委发布消息,...
重庆轨道交通18号线工程实现全线洞通 3月23日,重庆市住建委发布消息,... -
 武汉新洲区:消防培训进党校 上好消防安全“必修课” “如果真正进入火灾现场,请低头捂...
武汉新洲区:消防培训进党校 上好消防安全“必修课” “如果真正进入火灾现场,请低头捂... - 折扣大、优惠多 2023重庆春季房交会开幕 3月23日,2023重庆春季房地产暨家...
-
 【环球播资讯】游玩景点有哪些贵州 贵州旅游景点大全 1、黄果树大瀑布;黄果树大瀑布是中...
【环球播资讯】游玩景点有哪些贵州 贵州旅游景点大全 1、黄果树大瀑布;黄果树大瀑布是中... -
 世界最新:家庭吃什么面粉比较好 家庭最适合吃哪种面粉 1、家庭吃中筋面粉最好。2、家用面...
世界最新:家庭吃什么面粉比较好 家庭最适合吃哪种面粉 1、家庭吃中筋面粉最好。2、家用面... -
 校园默示录漫画全集(校园默示录h是哪集) 校园默示录漫画全集,校园默示录h...
校园默示录漫画全集(校园默示录h是哪集) 校园默示录漫画全集,校园默示录h... - 【速看料】抖音福袋全靠运气吗?如何抢到福袋? 提高抖音直播间人气最大的营销工具...